LLM + RL for agents
Training and evaluating agents that must act, not just answer, by bridging language understanding with sequential decision-making.
policy optimization for language agents • reward design • long-horizon tasks • evaluation

The Ohio State University · Computer Science
PhD student in AI
Research at the boundary of large language models (LLMs) and reinforcement learning (RL), with an emphasis on building systems that reliably reason, decide, and improve with experience.
I work on methods that connect language-based reasoning with decision-making and learning from interaction, aiming to make LLM-driven agents more robust, controllable, and effective on real tasks.
Advisor: Andrew Perrault
Training and evaluating agents that must act, not just answer, by bridging language understanding with sequential decision-making.
policy optimization for language agents • reward design • long-horizon tasks • evaluation
Methods for making improvements measurable and verifiable with explicit objectives, robust benchmarks, and careful feedback design.
process supervision • calibration • objective alignment • robust scoring
Building reproducible training and evaluation pipelines for large-scale experimentation with practical rigor.
distributed runs • reproducibility • toolchain reliability • experiment ops
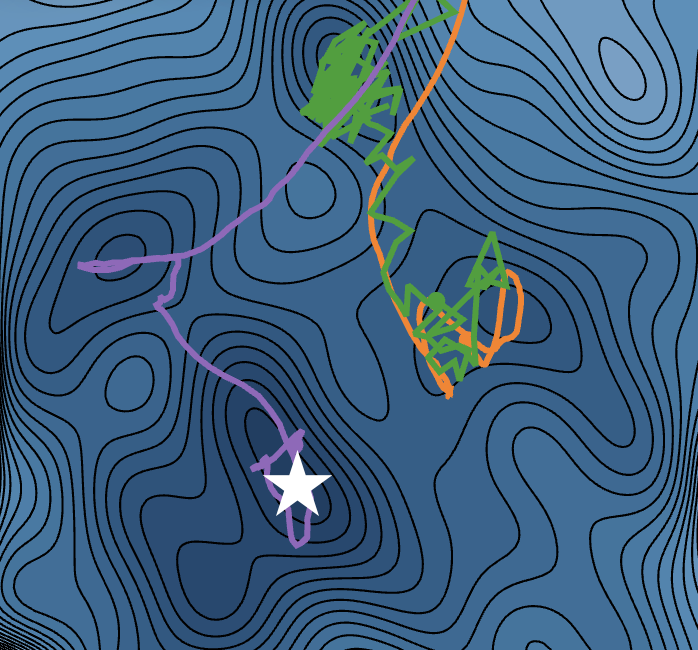
Interactive optimization arena and benchmark environment for studying optimizer behavior.
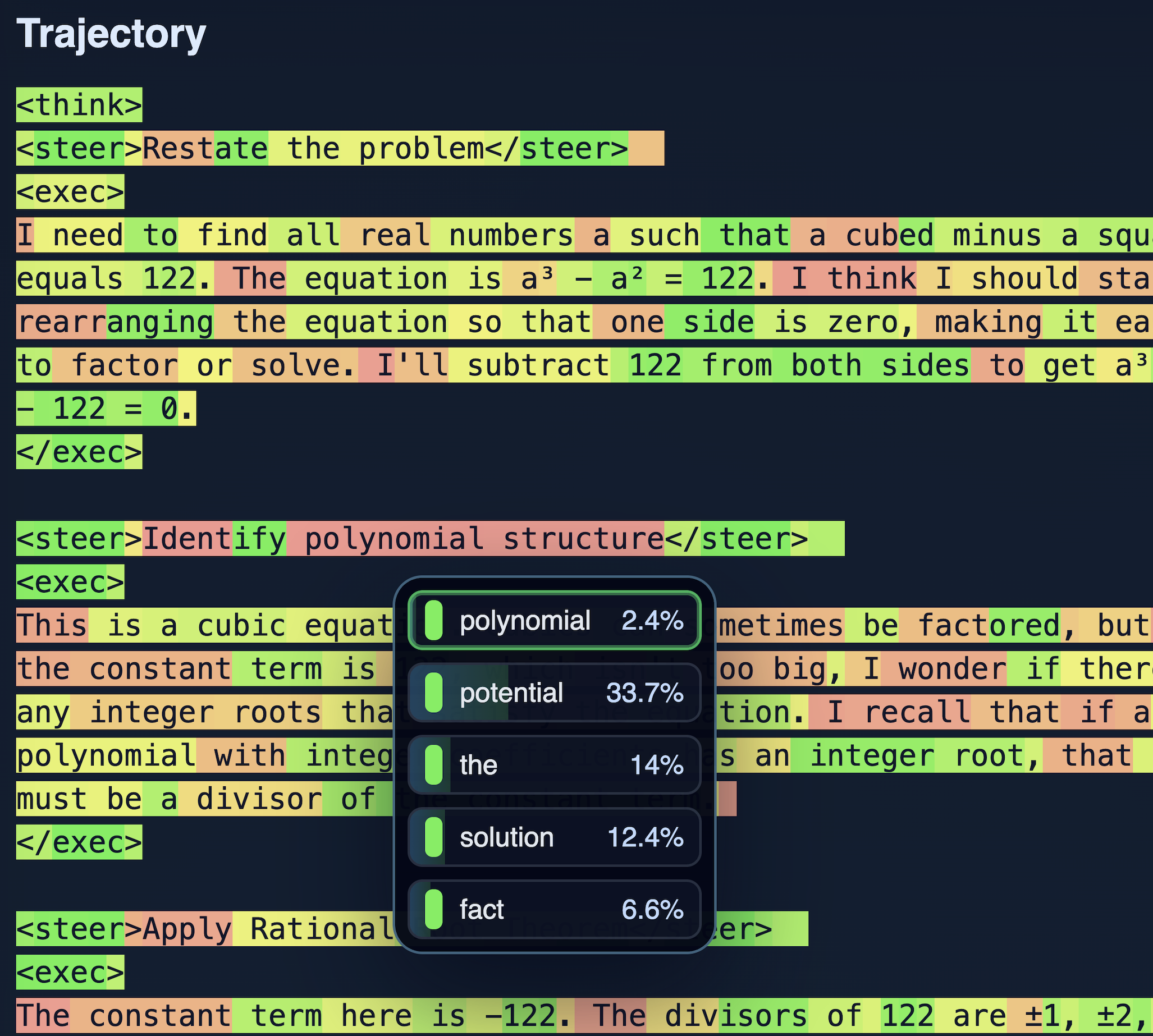
Framework for structuring language-agent reasoning and evaluating reliability across staged decomposition pipelines.
Standalone benchmarking and average@k style analyses for comparing model reasoning behavior under controlled settings.